
由于超算本身就是为了解决应用的算力需求,那么如何缓解云端的多任务、多租户资源分配,保证用户获得最佳性能,则是超算迈向云端时必须解决的问题。对此nvidia推出了云原生超级计算架构,以bluefield dpu为“智慧大脑”让用户获得极致性能,以更好地赋能创新,助力新场景应用。
从人工智能、基因测序到仿真模拟、气象海洋预报,一直以来高性能计算(hpc)应用越来越普及,其覆盖领域也迅速扩展。随着it技术的发展,尤其是开放架构和开源的日渐成熟,超算正与大数据、人工智能等技术加速融合,由此带来存储容量大、存储类型复杂、云原生部署需求等多方面的挑战。
值得关注的是,由于云端上的应用程序通常以分布式资源的方式运行,因此当超算被搬到云端后,势必面临多租户运行的复杂环境。由于超算本身就是为了解决应用的算力需求,那么如何缓解云端的多任务、多租户资源分配,保证用户获得最佳性能,则是超算迈向云端时必须解决的问题。对此nvidia推出了云原生超级计算架构,以bluefield dpu为“智慧大脑”让用户获得极致性能,以更好地赋能创新,助力新场景应用。
时不我待,云原生超级计算成为新引擎
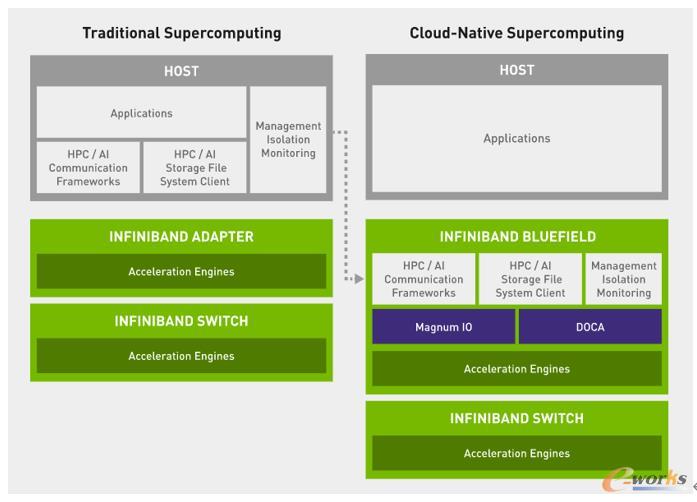
通常情况下,数据中心中各个角色泾渭分明:由cpu处理应用,gpu对应用进行加速,再通过网络搭建成一个大规模的数据中心。但在面对大规模的算力需求的时候,cpu除了完成自己的计算任务外,还需要“加班”去处理通信、存储、安全等任务,并平衡各个任务所需要的资源。这个时候,影响整体性能的“系统噪声(background noise)”就随之产生了,这是现有架构不可避免的短板。
但若是以dpu进行软件定义网络、存储和网络安全加速功能,让dpu来优化和同步不同工作之间的资源分配,或者通过dpu来实现计算和通讯的异步操作,包括计算和存储的异步操作,则可以消除干扰,提升系统整体性能。

nvidia 网络亚太区高级总监宋庆春介绍到,这也是为什么云原生超级计算被青睐,成为数据中心新架构的原因。通过将dpu、gpu、cpu三位一体构成一个新型数据中心架构,可以通过更低的成本或者更少的硬件构建更高性能的系统。
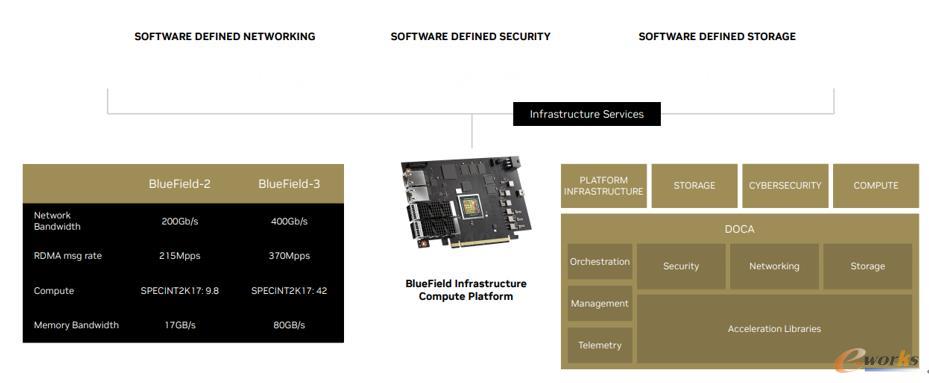
为提供更出色的性能,在nvidia云原生超级计算平台中,包含了nvidia bluefield dpu、infiniband网络、nvidia doca和magnum io。其中关键的是 nvidia bluefield dpu (数据处理器) 和高速、低延迟的 nvidia quantum infiniband 网络。
一方面,nvidia bluefield dpu 将先进的 nvidia connectx 网卡、配备pcie子系统的arm核心和定制设计的高性能计算硬件加速引擎相结合,可以针对通信和计算并行任务进行高度重叠处理,减少操作系统的“系统噪声(background noise)”,显著提高应用程序性能。另一方面,nvidia quantum infiniband 网络可加速并卸载数据传输,确保不会因数据或带宽限制而导致计算资源不足,并且nvidia quantum infiniband 网络可以在不同的用户或租户之间进行分区,提供安全性和服务质量 (qos) 保证。值得一提的是,借助 doca和magnum io,开发者可以通过创建高性能、软件定义和云原生 dpu 加速的服务,对未来的超级计算基础设施进行编程。
多维优势,重塑数据中心和云计算未来
实际上,nvidia的云原生超级计算凯发k8官网下载的解决方案已经获得业内诸多殊荣,也是最新的超级计算大会榜单上的常客:
·top500榜单的前一百名,infiniband网络占到63%;
·green500的top100榜单,infiniband网络占到75%;
·infiniband网络加速195个系统,与2021年11月top500榜单相比增长9%;
·nvidia infiniband网络和hopper gpu以65.09 gf/w排名green500第一。
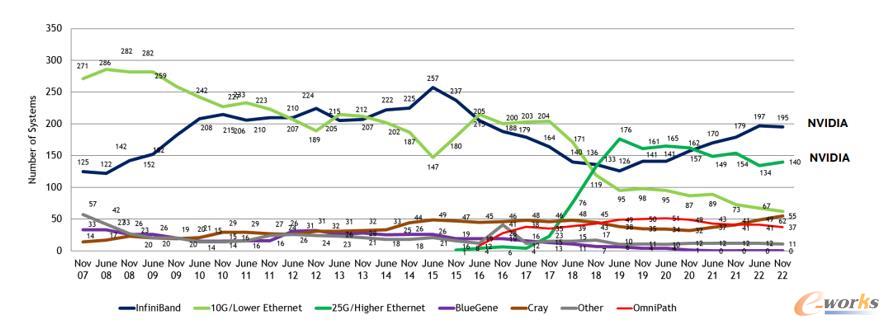
从上述一系列“成绩单”可以看出,无论是top500榜单还是green500榜单中,应用nvidia加速计算或者nvidia网络已经成为趋势,宋庆春介绍采用nvidia infiniband网络或采用nvidia infiniband网络加nvidia gpu的超级计算系统表现出众,且每年系统数量都在增长。
宋庆春表示通过nvidia bluefield dpu和nvidia doca,可以运行各种加速库,比如专门面向集合操作的ucc,专门面向点对点的ucx,专门面向存储、专门面向性能隔离专门面向网络编排的加速库,用于加速各种计算方面的业务,能够和标准的file system或者scheduler或者存储框架直接给应用提供标准接口,在用户无感知的情况下实现加速并享受到加速的优势。
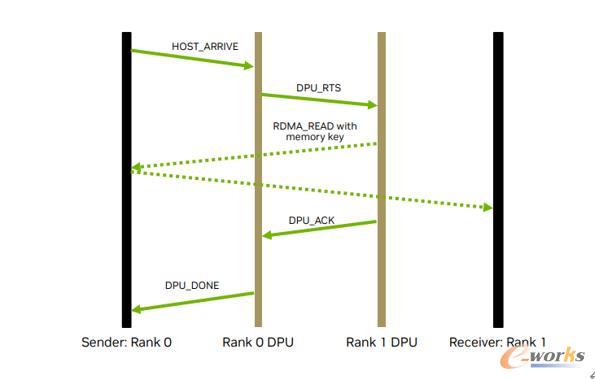
对此,宋庆春演示了dpu/doca如何加速通信流程的实例,当host发一个通知到dpu 后,dpu在收到通知后会和远端dpu进行沟通,随之直接在本地host memory和远端host memory建立通信通道,实现数据之间的传递。整个通信过程中,所有操作都由 dpu app 监视,不需要cpu参与,cpu只是发出通知,由dpu进行管理和执行。
此外,宋庆春强调云原生超级计算离不开的交换机计算sharp技术,这是迄今为止英伟达独有的技术,在交换机上可进行数据的aggregation和reduction,消除网络拥塞,突破网络物理带宽的限制。
可以看出,云原生超级计算将高性能计算的强大性能与云计算服务的安全性和易用性融于一体,可以简单安全地提供裸机性能、用户管理和隔离、数据保护和按需高性能计算以及ai服务。例如困扰用户的性能隔离问题,nvidia quantum-2 infiniband 平台提供创新的主动监控和拥塞管理,以实现流量隔离,几乎完全消除性能抖动,确保可预测的性能,就像应用程序在专用系统上运行一样。
激发创新,2022秋季dpu中国黑客松竞赛回顾
继第一届 dpu 中国虚拟黑客松(hackathon)竞赛在2022年4月16日至17日圆满收官之后,nvidia于2022年10月22日至23日发起并主办了2022秋季dpu中国黑客松竞赛。nvidia 网络技术专家崔岩介绍本次秋季dpu中国黑客松竞赛从8月开始进行筹备工作,9月12日开始官方招募,总共27支团队注册报名参赛,13支团队参加最终比赛,包括51位开发者,6位女性开发者。10月19日针对这些参赛队伍和中国doca社区开发者,nvidia提供了一次黑客松训练营,总共吸引超过3,500人参与,上万人次的观看。10月22日正式开启比赛,比赛是二十四小时竞赛时间,参赛团队会在此期间按照设立的项目去做相应的开发。

谈到本届和上届在选题上的区别,崔岩表示nvidia bluefield dpu和nvidia doca在云原生超级计算架构里面也是一个关键组成部分,所以在这二十四小时的竞赛中,nvidia要求参赛团队围绕使用nvidia bluefield dpu和nvidia doca实现rdma加速存储与ai的凯发k8官网下载的解决方案。
最终,sdic 团队项目获得了一等奖,其项目名称是《基于bluefield dpu数据中心 rdma虚拟化的研究》,主要是基于virtio的方案。由于virtio是io 半虚拟化的凯发k8官网下载的解决方案,也是一套通用的 io 设备虚拟化程序,所以会对半虚拟化io设备进行抽象,可对上层应用和各种hypervisor虚拟化设备提供通信框架和编程接口,减少跨平台带来的兼容性问题,提高驱动程序的开发效率。
在崔岩看来,dpu中国黑客松是开发者学习、实践使用nvidia doca软件开发套件的一个很好的活动平台,参赛者可以基于nvidia bluefield dpu去进行各种数据中心应用程序的开发。参赛团队可以利用doca驱动、doca库、开发工具和相关文档构建、优化nvidia bluefield dpu,去做基础设施相关的加速应用开发,在此过程中展现他们的奇思妙想、创新精神和团队气质,也为未来基于nvidia bluefield dpu的持续创新提供了源头活水。
值得关注的是,由于云端上的应用程序通常以分布式资源的方式运行,因此当超算被搬到云端后,势必面临多租户运行的复杂环境。由于超算本身就是为了解决应用的算力需求,那么如何缓解云端的多任务、多租户资源分配,保证用户获得最佳性能,则是超算迈向云端时必须解决的问题。对此nvidia推出了云原生超级计算架构,以bluefield dpu为“智慧大脑”让用户获得极致性能,以更好地赋能创新,助力新场景应用。
图1 云原生超级计算架构的支柱 - nvidia bluefield dpu
时不我待,云原生超级计算成为新引擎
通常情况下,数据中心中各个角色泾渭分明:由cpu处理应用,gpu对应用进行加速,再通过网络搭建成一个大规模的数据中心。但在面对大规模的算力需求的时候,cpu除了完成自己的计算任务外,还需要“加班”去处理通信、存储、安全等任务,并平衡各个任务所需要的资源。这个时候,影响整体性能的“系统噪声(background noise)”就随之产生了,这是现有架构不可避免的短板。
但若是以dpu进行软件定义网络、存储和网络安全加速功能,让dpu来优化和同步不同工作之间的资源分配,或者通过dpu来实现计算和通讯的异步操作,包括计算和存储的异步操作,则可以消除干扰,提升系统整体性能。
图2 nvidia 网络亚太区高级总监宋庆春
nvidia 网络亚太区高级总监宋庆春介绍到,这也是为什么云原生超级计算被青睐,成为数据中心新架构的原因。通过将dpu、gpu、cpu三位一体构成一个新型数据中心架构,可以通过更低的成本或者更少的硬件构建更高性能的系统。
图3 从传统架构向云原生超级计算架构演进
为提供更出色的性能,在nvidia云原生超级计算平台中,包含了nvidia bluefield dpu、infiniband网络、nvidia doca和magnum io。其中关键的是 nvidia bluefield dpu (数据处理器) 和高速、低延迟的 nvidia quantum infiniband 网络。
一方面,nvidia bluefield dpu 将先进的 nvidia connectx 网卡、配备pcie子系统的arm核心和定制设计的高性能计算硬件加速引擎相结合,可以针对通信和计算并行任务进行高度重叠处理,减少操作系统的“系统噪声(background noise)”,显著提高应用程序性能。另一方面,nvidia quantum infiniband 网络可加速并卸载数据传输,确保不会因数据或带宽限制而导致计算资源不足,并且nvidia quantum infiniband 网络可以在不同的用户或租户之间进行分区,提供安全性和服务质量 (qos) 保证。值得一提的是,借助 doca和magnum io,开发者可以通过创建高性能、软件定义和云原生 dpu 加速的服务,对未来的超级计算基础设施进行编程。
多维优势,重塑数据中心和云计算未来
实际上,nvidia的云原生超级计算凯发k8官网下载的解决方案已经获得业内诸多殊荣,也是最新的超级计算大会榜单上的常客:
·top500榜单的前一百名,infiniband网络占到63%;
·green500的top100榜单,infiniband网络占到75%;
·infiniband网络加速195个系统,与2021年11月top500榜单相比增长9%;
·nvidia infiniband网络和hopper gpu以65.09 gf/w排名green500第一。
从上述一系列“成绩单”可以看出,无论是top500榜单还是green500榜单中,应用nvidia加速计算或者nvidia网络已经成为趋势,宋庆春介绍采用nvidia infiniband网络或采用nvidia infiniband网络加nvidia gpu的超级计算系统表现出众,且每年系统数量都在增长。
图4 2022年11月top 500网络互连方案趋势
宋庆春表示通过nvidia bluefield dpu和nvidia doca,可以运行各种加速库,比如专门面向集合操作的ucc,专门面向点对点的ucx,专门面向存储、专门面向性能隔离专门面向网络编排的加速库,用于加速各种计算方面的业务,能够和标准的file system或者scheduler或者存储框架直接给应用提供标准接口,在用户无感知的情况下实现加速并享受到加速的优势。
对此,宋庆春演示了dpu/doca如何加速通信流程的实例,当host发一个通知到dpu 后,dpu在收到通知后会和远端dpu进行沟通,随之直接在本地host memory和远端host memory建立通信通道,实现数据之间的传递。整个通信过程中,所有操作都由 dpu app 监视,不需要cpu参与,cpu只是发出通知,由dpu进行管理和执行。
图5 典型的dpu/doca卸载及加速通信流程
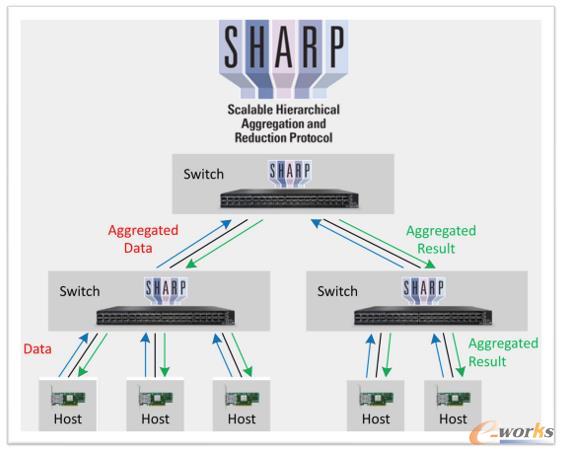
此外,宋庆春强调云原生超级计算离不开的交换机计算sharp技术,这是迄今为止英伟达独有的技术,在交换机上可进行数据的aggregation和reduction,消除网络拥塞,突破网络物理带宽的限制。
图6 sharp 网络计算示例
可以看出,云原生超级计算将高性能计算的强大性能与云计算服务的安全性和易用性融于一体,可以简单安全地提供裸机性能、用户管理和隔离、数据保护和按需高性能计算以及ai服务。例如困扰用户的性能隔离问题,nvidia quantum-2 infiniband 平台提供创新的主动监控和拥塞管理,以实现流量隔离,几乎完全消除性能抖动,确保可预测的性能,就像应用程序在专用系统上运行一样。
激发创新,2022秋季dpu中国黑客松竞赛回顾
继第一届 dpu 中国虚拟黑客松(hackathon)竞赛在2022年4月16日至17日圆满收官之后,nvidia于2022年10月22日至23日发起并主办了2022秋季dpu中国黑客松竞赛。nvidia 网络技术专家崔岩介绍本次秋季dpu中国黑客松竞赛从8月开始进行筹备工作,9月12日开始官方招募,总共27支团队注册报名参赛,13支团队参加最终比赛,包括51位开发者,6位女性开发者。10月19日针对这些参赛队伍和中国doca社区开发者,nvidia提供了一次黑客松训练营,总共吸引超过3,500人参与,上万人次的观看。10月22日正式开启比赛,比赛是二十四小时竞赛时间,参赛团队会在此期间按照设立的项目去做相应的开发。
图7 nvidia 网络技术专家崔岩
谈到本届和上届在选题上的区别,崔岩表示nvidia bluefield dpu和nvidia doca在云原生超级计算架构里面也是一个关键组成部分,所以在这二十四小时的竞赛中,nvidia要求参赛团队围绕使用nvidia bluefield dpu和nvidia doca实现rdma加速存储与ai的凯发k8官网下载的解决方案。
最终,sdic 团队项目获得了一等奖,其项目名称是《基于bluefield dpu数据中心 rdma虚拟化的研究》,主要是基于virtio的方案。由于virtio是io 半虚拟化的凯发k8官网下载的解决方案,也是一套通用的 io 设备虚拟化程序,所以会对半虚拟化io设备进行抽象,可对上层应用和各种hypervisor虚拟化设备提供通信框架和编程接口,减少跨平台带来的兼容性问题,提高驱动程序的开发效率。
在崔岩看来,dpu中国黑客松是开发者学习、实践使用nvidia doca软件开发套件的一个很好的活动平台,参赛者可以基于nvidia bluefield dpu去进行各种数据中心应用程序的开发。参赛团队可以利用doca驱动、doca库、开发工具和相关文档构建、优化nvidia bluefield dpu,去做基础设施相关的加速应用开发,在此过程中展现他们的奇思妙想、创新精神和团队气质,也为未来基于nvidia bluefield dpu的持续创新提供了源头活水。
责任编辑:

e-works
官方微信
官方微信

掌上
信息化
信息化
排行榜
编辑推荐
文章推荐
博客推荐
视频推荐
- 2022/11/15
- 2022/11/15
- 2022/11/3