

这款全新aiu芯片是ibm研究院ai硬件中心投入五年开发出的成果。ai硬件中心专注于开发下一代芯片与ai系统,计划每年将ai硬件效率提升2.5倍,并希望在十年间(2019年至2029年)将ai模型的训练和运行速度拉高1000倍。
aiu大解密
根据ibm发布的博文,“我们的完整片上系统共有32个处理核心和230亿个晶体管——与我们z16芯片的晶体管数量大致相同。ibm aiu在设计易用性方面与普通显卡相当,能够接入任何带有pci插槽的计算机或服务器。”
深度学习模型在传统上,一直依赖于cpu加gpu协处理器的组合进行训练与运行。gpu最初是为沉浸图形图像而开发,但后来人们发现该技术在ai领域有着显著的使用优势。
ibm aiu并非图形处理器,而是专为深度学习模型加速而生,针对矩阵和矢量计算进行了设计优化。aiu能够解决高复杂度计算问题,并以远超cpu的速度执行数据分析。
ai与深度学习的发展
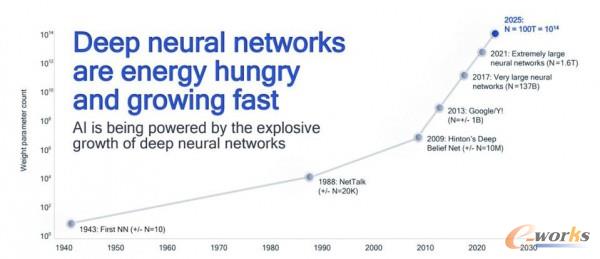
深度神经网络极为耗能,但也发展迅猛
深度学习的发展给算力资源带来了巨大压力。ai与深度学习模型在各个行业的普及度呈现出指数级增长,如今几乎每个角落都浮动着智能元素的身影。
除了普及度提升之外,模型大小也堪称一路狂飙。深度学习模型往往体量庞大,包含数十亿甚至数万亿个参数。遗憾的是,根据ibm的说法,硬件效率的发展已经无法跟上深度学习的指数级膨胀。
近似计算
从历史上看,计算一般集中在高精度64位与32位浮点运算层面。但ibm认为,有些计算任务并不需要这样的精度,于是提出了降低传统计算精度的新术语——近似计算。ibm在博文中对于近似计算的基本原理做出如下说明:
“对于常见的深度学习任务,我们真的需要那么高的计算精度吗?没有高分辨率图像,难道我们的大脑就无法分辨家人或者小猫?当我们进行一轮文本线程搜索时,难道第50002条答案跟第50003条之间的顺序必须严格区分?答案当然是否定的,所以如此种种的诸多任务都可以通过近似计算来处理。”
近似计算在新aiu芯片的设计中也发挥着至关重要的作用。ibm研究人员设计的aiu芯片精度低于cpu,而这种较低精度也让新型aiu硬件加速器获得了更高的计算密度。ibm使用混合8位浮点(hfp)计算,而非ai训练中常见的32位或16点浮点计算。由于精度较低,因此该芯片的运算执行速度可达到fp16的2倍,同时继续保持类似的训练效能。
这种看似相互冲突的设计目标,在ibm眼中却是和谐统一、顺畅自然。具体来讲,既要靠低精度计算获得更高的算力密度和更快的计算速度,同时又要保证深度学习(dl)模型的准确率与高精度计算保持一致。
ibm设计的这款芯片就是为了简化ai工作流而生。蓝色巨人解释道,“由于大多数ai计算都涉及矩阵和矢量乘法,所以我们的芯片架构采用了比通用型cpu更简单的布局。ibm将aiu设计为直接将数据从一个计算引擎发送至另一计算引擎,由此大大削减了运行功耗。”
性能表现
ibm在公告中并未提到多少关于该芯片的技术信息。但回顾ibm在2021年国际固态电路会议(isscc)上展示的早期7纳米芯片设计性能,应该可以据此估算出最新aiu的大致性能水平。
ibm在会上展示的原型并非32核心,而一块实验性的4核心7纳米ai芯片,支持fp16与混合fp8格式,可用于深度学习模型的训练和推理。它还支持用于扩展推理的int4和int2格式。2021年lindley group在通讯中公布了这款原型芯片的性能摘要,相关报道如下:
在峰值速度并使用hfp 8时,这款7纳米芯片设计方案实现每秒每瓦特1.9 teraflops(tf/w)。
tops衡量的是加速器在1秒之内可以解决多少数学问题,可用于比较不同加速器在特定推理任务上的处理能力。在使用int4进行推理时,这款实验芯片可达到16.5 tops/w,优于高通的低功耗cloud ai模组。
分析师笔记
虽然规格不明、价格未定,但估计ibm这款aiu的定价可能在1500美元到2000美元之间。如果价格设定合理,相信aiu能够在市场上迅速确立其地位。
由于缺乏细节信息,暂时无法直接对aiu和gpu的ai处理核心进行比较。
aiu中使用的低精度技术基于ibm研究院的早期研究成果,其先后开创了首个以16位低精度系统执行深度学习训练、首个8位训练技术以及最先进的2位推理技术。
根据ibm研究院的介绍,aiu使用到了telum芯片中ai加速器的缩放版本。
telum使用的是7纳米晶体管,但aiu将使用更先进的5纳米晶体管。
如果aiu能够及时参与明年的mlperf基准测试,相信结果会非常有趣。我们也将持续关注ibm这款新成果的更多动态。
责任编辑:
本文为授权转载文章,任何人未经原授权方同意,不得复制、转载、摘编等任何方式进行使用,e-works不承担由此而产生的任何法律责任! 如有异议请及时告之,以便进行及时处理。凯发k8官网下载的联系方式:editor@e-works.net.cn tel:027-87592219/20/21。

e-works
官方微信
官方微信

掌上
信息化
信息化
排行榜
编辑推荐
文章推荐
博客推荐
视频推荐
- 2022/11/3
- 2022/11/3
- 2022/11/3